性能调优
for 循环装饰器
As discussed in previous topics, Taichi kernels automatically parallelize for-loops in the outermost scope. Our compiler sets the settings automatically to best explore the target architecture. Nonetheless, for Ninjas seeking the final few percent of speed, we give several APIs to allow developers to fine-tune their programs. Specifying a proper block_dim, for example, might result in a nearly 3x speed gain in examples/mpm3d.py.
You can use ti.loop_config to set the loop directives for the next for loop. Available directives are:
- parallelize: Sets the number of threads to use on CPU
- block_dim: Sets the number of threads in a block on GPU
- serialize: If you set serialize to
True, the for loop will run serially, and you can write break statements inside it (Only applies on range/ndrange fors). Equals to setting parallelize to 1.
@ti.kernel
def break_in_serial_for() -> ti.i32:
a = 0
ti.loop_config(serialize=True)
for i in range(100): # This loop runs serially
a += i
if i == 10:
break
return a
break_in_serial_for() # returns 55
n = 128
val = ti.field(ti.i32, shape=n)
@ti.kernel
def fill():
ti.loop_config(parallelize=8, block_dim=16)
# If the kernel is run on the CPU backend, 8 threads will be used to run it
# If the kernel is run on the CUDA backend, each block will have 16 threads.
for i in range(n):
val[i] = i
后台:GPU 线程架构
It is worthy to quickly discuss the thread hierarchy on contemporary GPU architectures in order to help you understand how the previously mentioned for-loop is parallelized.
From fine-grained to coarse-grained, the computation units are as follows: iteration, thread, block, and grid.
- Iteration: The body of a for-loop is an iteration. Each iteration corresponds to a different
ivalue in the for-loop. - Thread: Iterations are classified as threads. A thread is the smallest parallelized unit. All iterations inside a thread are serial in nature. To maximize parallel efficiency, we normally employ one iteration per thread.
- Block: Threads are organized into groups called blocks. All threads within a block are executed in parallel and can share block local storage.
- Grid: Blocks are grouped into grids. A grid is the minimal unit that is launched from the host. All blocks within a grid are executed in parallel. In Taichi, each parallelized for-loop is represented as a grid.
For more details, please see the CUDA C programming guide. Note that we employ the CUDA terminology here, other backends such as OpenGL and Metal follow a similar thread hierarchy.
示例:调整 for 循环的块级别并行
Programmers may prepend some decorator(s) to tweak the property of a for-loop, e.g.:
@ti.kernel
def func():
for i in range(8192): # no decorator, use default settings
...
ti.loop_config(block_dim=128) # change the property of next for-loop:
for i in range(8192): # will be parallelized with block_dim=128
...
for i in range(8192): # no decorator, use default settings
...
数据布局
Because Taichi separates data structures from computation, developers may experiment with alternative data layouts. Choosing an efficient layout, like in other programming languages, may significantly enhance performance. Please consult the Fields (advanced) section for further information on advanced data layouts in Taichi.
局部存储优化
Taichi has a few speed enhancements that take use of fast memory (e.g., CUDA shared memory, L1 cache). Simply, Taichi replaces access to global memory (slow) with access to local memory (quick) wherever feasible, and writes data in local memory (e.g., CUDA shared memory) back to global memory at the conclusion. Such changes keep the original program's semantics (will be explained later).
线程局部存储(TLS)
TLS is mostly designed to optimize parallel reduction. When Taichi identifies a global reduction pattern in a @ti.kernel, it automatically applies the TLS optimizations during code generation, similar to those found in common GPU reduction implementations.
We will walk through an example using CUDA's terminology.
x = ti.field(ti.f32, shape=1000000)
s = ti.field(ti.f32, shape=())
@ti.kernel
def sum():
for i in x:
s[None] += x[i]
sum()
Taichi's parallel loop is implemented internally with Grid-Stride Loops. This means that each physical CUDA thread may handle several items in x. In other words, the number of threads started for sum can be less than the shape of x.
One optimization offered by this method is the substitution of a thread-local memory access for a global memory access. Instead of directly and atomically adding x[i] to the global memory destination s[None], Taichi preallocates a thread-local buffer upon entering the thread, accumulates (non-atomically) the value of x into this buffer, and then atomically adds the result of the buffer back to s[None] before exiting the thread. If each thread handles N items in x, the number of atomic additions is reduced to one-Nth of its original amount.
Additionally, the last atomic add to the global memory s[None] is optimized using CUDA's warp-level intrinsics, further reducing the number of required atomic adds.
Currently, Taichi supports TLS optimization for these reduction operators: add, sub, min and max on 0D scalar/vector/matrix ti.fields. It is not yet supported on ti.ndarrays. Here is a benchmark comparison when running a global max reduction on a 1-D Taichi field of 8M floats on an Nvidia GeForce RTX 3090 card:
- TLS disabled: 5.2 x 1e3 us
- TLS enabled: 5.7 x 1e1 us
TLS has resulted in a 100x increase in speed. We also demonstrate that TLS reduction sum achieves equivalent performance to CUDA implementations; for more information, see the benchmark report.
块局部存储(BLS)
Context: For a sparse field whose last layer is a dense SNode (i.e., its layer hierarchy matches ti.root.(sparse SNode)+.dense), Taichi will assign one CUDA thread block to each dense container (or dense block). BLS optimization works specifically for such kinds of fields.
BLS intends to enhance stencil computing processes by utilizing CUDA shared memory. This optimization begins with users annotating the set of fields they want to cache using ti.block local. At compile time, Taichi tries to identify the accessing range in relation to the dense block of these annotated fields. If Taichi is successful, it creates code that first loads all of the accessible data in range into a block local buffer (CUDA's shared memory), then replaces all accesses to the relevant slots into this buffer.
Here is an example illustrating the usage of BLS. a is a sparse field with a block size of 4x4.
a = ti.field(ti.f32)
b = ti.field(ti.f32)
# `a` has a block size of 4x4
ti.root.pointer(ti.ij, 32).dense(ti.ij, 4).place(a)
@ti.kernel
def foo():
# Taichi will cache `a` into the CUDA shared memory
ti.block_local(a)
for i, j in a:
print(a[i - 1, j], a[i, j + 2])
Each loop iteration accesses items with an offset [-1, 0] and [0, 2] to its coordinates, respectively. Therefore, for an entire block spanning from [M, N] (inclusive) to [M + 4, N + 4] (exclusive), the accessed range w.r.t this block is [M - 1, M + 4) x [N, N + 6) (derived from [M + (-1), M + 4) x [N, N + 4 + 2)). The mapping between the global coordinates i, j and the local indices into the buffer is shown below:
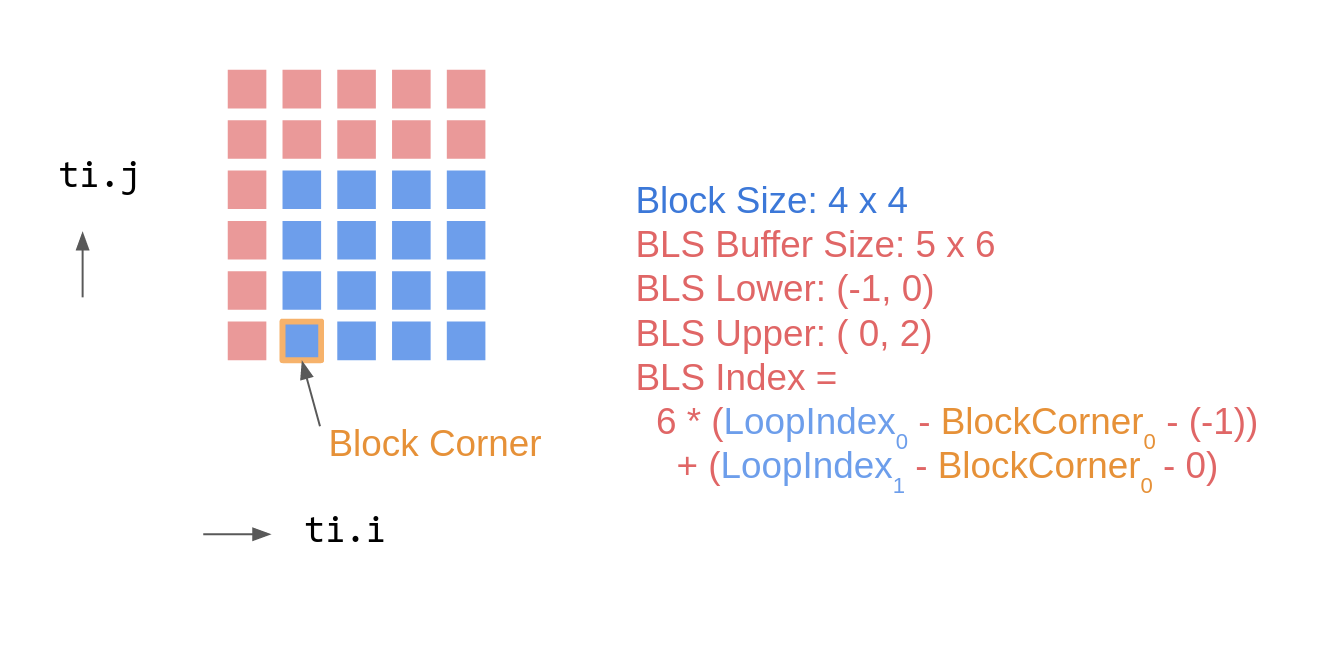
You do not need to be concerned about these fundamental elements as a user. Taichi automatically does all inference and global/block-local mapping. That is, Taichi will preallocate a CUDA shared memory buffer of size 5x6, preload a's contents into this buffer, then replace all a (global memory) accesses with the buffer in the loop body. While this basic example does not change a itself, if a block-cached field is written, Taichi produces code that returns the buffer to global memory.
note
BLS does not come cheap. Remember that BLS is intended for stencil computations with a high number of overlapping global memory accesses. If this is not the case, pre-loading and post-storing may actually degrade performance.
Furthermore, recent generations of Nvidia GPU cards have closed the read-only access gap between global memory and shared memory. Currently, we discovered that BLS is more effective for storing the destinations of atomic actions.
As a general rule of thumb, we recommend running benchmarks to determine whether or not you should enable BLS.
离线缓存
The first time a Taichi kernel is called, it is implicitly compiled. To decrease the cost in subsequent function calls, the compilation results are retained in an online in-memory cache. The kernel can be loaded and launched immediately as long as it remains unaltered. When the application exits, the cache is no longer accessible. When you restart the programme, Taichi must recompile all kernel routines and rebuild the online in-memory cache. Because of the compilation overhead, the first launch of a Taichi function can typically be slow.
为解决这一问题,我们新增离线缓存功能,将编译缓存转储到磁盘上,以备后续运行使用。 重复运行时,第一次启动的开销可大幅减少。 Taichi 现在默认构建、维护一个离线缓存,并在 ti. nit() 中提供数个选项用于配置离线缓存行为。
offline_cache: bool:启用或禁用离线缓存。 默认:True。offline_cache_file_path: str:存放离线缓存文件的目录。 默认:Windows 系统中:'C:\taichi_cache\ticache\';类 unix 系统中:'~/.cache/taichi/ticache/'。 自动填充目录。offline_cache_max_size_of_files: int32:缓存文件的最大字节大小。 默认:100MB。 当缓存文件大小超过此限制时触发清理过程。offline_cache_cleaning_policy: str:更替缓存中陈旧文件的策略。 选项:'never'、'version'、'lru'和'fifo'。 默认:'lru'。'never':不管offline_cache_max_size_of_files配置如何,从不清理任何缓存文件;'version':仅弃置与 kernel 函数相关的旧版本缓存文件;'lru':弃置最近使用最少的缓存文件;'fifo':弃置最早添加的缓存文件。
要验证效果,请选择示例运行两次,并观察启动开销: 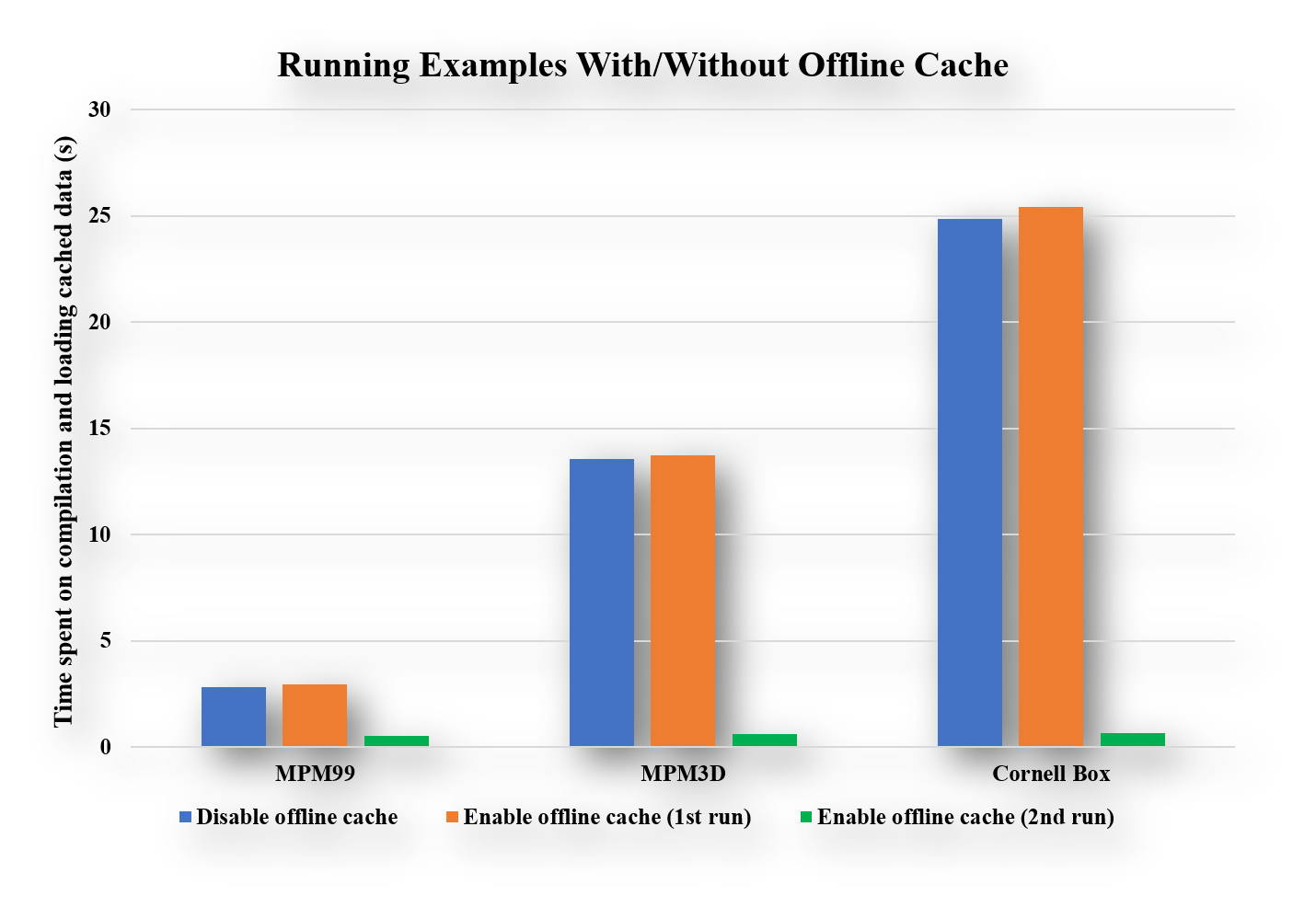
note
If your code behaves abnormally, disable offline cache by setting the environment variable TI_OFFLINE_CACHE=0 or offline_cache=False in the ti.init() method call and file an issue with us on Taichi's GitHub repo.