为什么需要一门新的编程语言
不妨想象你正在编写基于粒子的流体算法。 要开始并不难,你不费工夫就在网上找到可供参考的 C++/CUDA 作品(或者意外发现这就出自实验室伙伴之手)。 cmake .. && make,你打下一行指令。 糟糕!Cmake 抛出错误提醒,某个第三方库不能兼容。 安装、重新编译...... 这次没问题了。 然后你运行程序,却又出现了段错误(当然,还没有堆栈跟踪信息)。 你愁眉苦脸地紧盯着代码,把必要的资产文件放到正确的位置,修复了几个野指针,然后重新运行。 这次终于跑通了...... 但别急着高兴,你还要接入改良后的算法。 又是一场与 GPU 或 CPU 代码的苦战。 很多时候,你只是迷失在编程语言的细节问题中。
如果这一切听起来都过于熟悉,那么恭喜你!你可能能在这里找到解决方法!
Taichi 起步于 MIT 的计算机科学与人工智能实验室(CSAIL),设计初衷是便利计算机图形学研究人员的日常工作,帮助他们快速实现适用于 GPU 的视觉计算和物理模拟算法。 Taichi 选择了一条创新的路径:嵌入于 Python,使用即时编译(JIT)架构(如 LLVM、SPIR-V),将 Python 源代码转化为 GPU 或 CPU 的原生指令,在开发时和运行时均提供优越性能。
当然,以 Python 为前端的领域特定语言(DSL)不是什么新奇的创造。 过去几年里,Halide、PyTorch、TVM 等框架发展成熟,实际已塑造了图像处理、深度学习等领域的标准。 Taichi 与这些框架的最大区别在于其指令式编程范式。 作为一种领域特定语言,Taichi 并不专长于特定的某种计算模式。 这意味着更大的灵活度。 也许有人会假定灵活性需要牺牲优化程度,但对 Taichi 而言并非如此,主要有以下几个原因:
- Taichi 的工作负荷呈现出不可利用的特点(如不支持逐元素运算),也就是说算法强度是固定不变的。 只要切换到 GPU 后端,用户就可以收获明显的性能提升。
- 传统深度学习框架使用的运算符都是简单的数学表达式,需要在计算图层面融合运算符,以实现更高的算法强度。但 Taichi 的指令式编程让用户能在一个 kernel 中轻松完成大量计算。 我们将这样的 kernel 命名为 mega-kernel。
- Taichi 使用各种编译器技术大幅优化源代码,包括公共子表达式消除、死码删除、控制流图分析。 这些优化手段适用于各个后端,因为 Taichi 有自己的中间表示(IR)层。
- 即时编译提供了更多的优化机会。
尽管如此,Taichi 远不止于一个 Python 的即时转译器。 最初的设计目标之一是将计算与数据结构解耦。 为此,Taichi 提供一套通用的数据容器,叫做 SNode (/ˈsnoʊd/)。 SNode 可以方便地构造或稠密或稀疏的多维 field,并形成清晰的层级。 在 AoS 和 SoA 两种内存布局间切换只需不到 10 行代码。 这启发了很多数值模拟领域的使用案例。 If you are interested to learn them, please check out Fields (advanced), Spatially Sparse Data Structures, or the original Taichi paper.
我们将解耦的概念进一步延伸到数据类型。 由于 GPU 内存容量和带宽已成为当前的主要瓶颈,让每个内存单位存储更多的数据变得至关重要。 2021 年,Taichi 引入了可定制量化类型, 允许定义任意位数的定点数或浮点数(但仍不能超过 64 位)。 从此,在单个 GPU 设备上进行超 4 亿粒子的 MPM 模拟成为可能。 论文《QuanTaichi》对此进行了详细介绍。
Taichi 是直观的语言。 如果你使用 Python,你就能使用 Taichi。 当你用 Taichi 编程,程序自动选择在 GPU 运行(CPU 为替补)。 Taichi 问世后,这样一个并不复杂的理念有幸获得了诸多关注,在众多贡献者的努力下,现在 Taichi 支持更多后端,包括 Vulkan、OpenGL,和 Direct X(仍在进展中)。 没有一个强大且专注的社区,Taichi 无法走到今天。
展望未来,前路不乏机遇,在这里愿与大家分享一些我们的愿景。
学术届
研究工作中,90% 的代码都逃不开被弃如敝履的命运,因为研究的本质就是不断打破假设、迭代观念。 一味匆忙赶代码却不考虑性能可能导向错误的结论,而过早开始优化性能又往往只是浪费时间、一无所得。 因此,一个性能与生产力两全的选项将对学术研究大有裨益。
Taichi 会继续服务于学术界。 我们为高性能计算研究项目设计的(或计划设计的)关键功能包括(kernel 内的)小规模线性代数、 大规模稀疏系统,以及对结构化和非结构化数据的高效近邻读取。
Taichi 也利用(IR 层)源代码转换实现了一个自动微分模块,因此为机器学习项目提供了称手的工具。
应用与游戏引擎
Taichi 的一大优势在于可移植性,支持多种后端。 在开发过程中,我们意识到各行业用户对多平台打包和部署的需求日益增长。 下方动图是将 Taichi 和 Unity 结合的一个实验性成果。 我们将 Taichi kernel 导出为 SPIR-V 着色器,可以将它们轻松导入到 Unity 项目中。
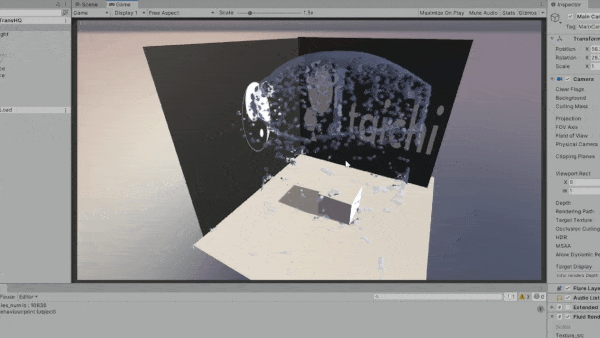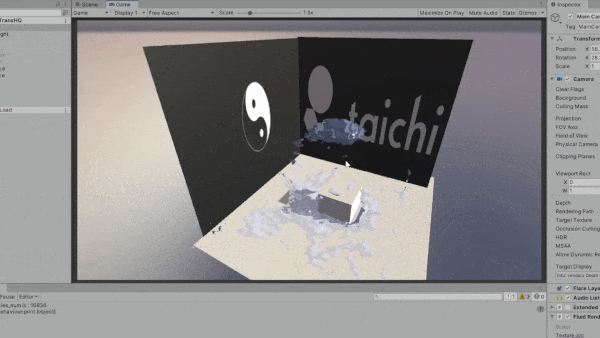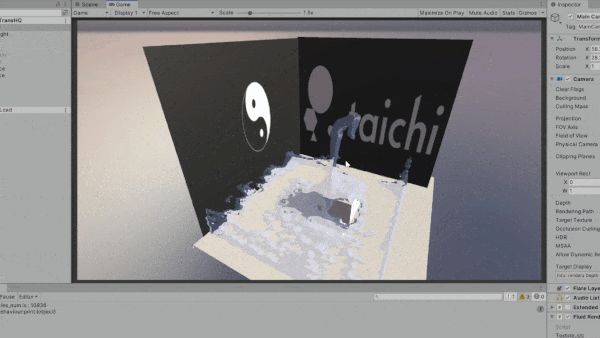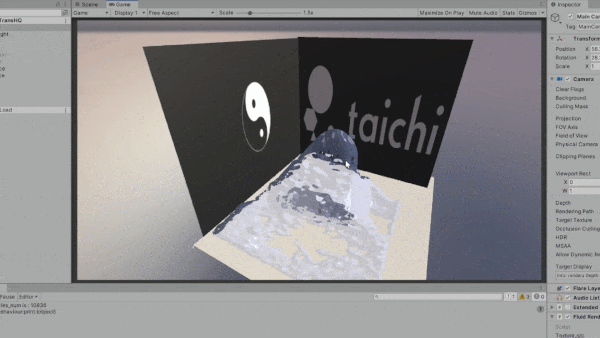
通用计算
虽然 Taichi 初衷是便利物理模拟,但借助 GPU 通用计算,Taichi 实际在多个领域得到应用。
- taichimd:基于 Taichi 编程语言的 GPU 加速交互式(宏观)分子动态仿真。
- TaichiSLAM:用 Taichi 语言构建 SLAM(即时定位和地图构建)的后端 3D 稠密建图库,可用于无人机集群。
- Stannum:将 Taichi 与 PyTorch 结合。
新前端?没什么不可能
采用编译器模式的好处是可以解耦前后端。 Taichi 目前嵌入于 Python,但谁说一定要一成不变呢? 保持关注:-)